Smartphone Photo Scanning and Restoration
Created a semi-supervised pipeline and dataset for restoring smartphone-scanned images.

Created a semi-supervised pipeline and dataset for restoring smartphone-scanned images.
Developed Latent Diffusion Models with histopathology pretraining to restore frozen tissue images for diagnostic accuracy.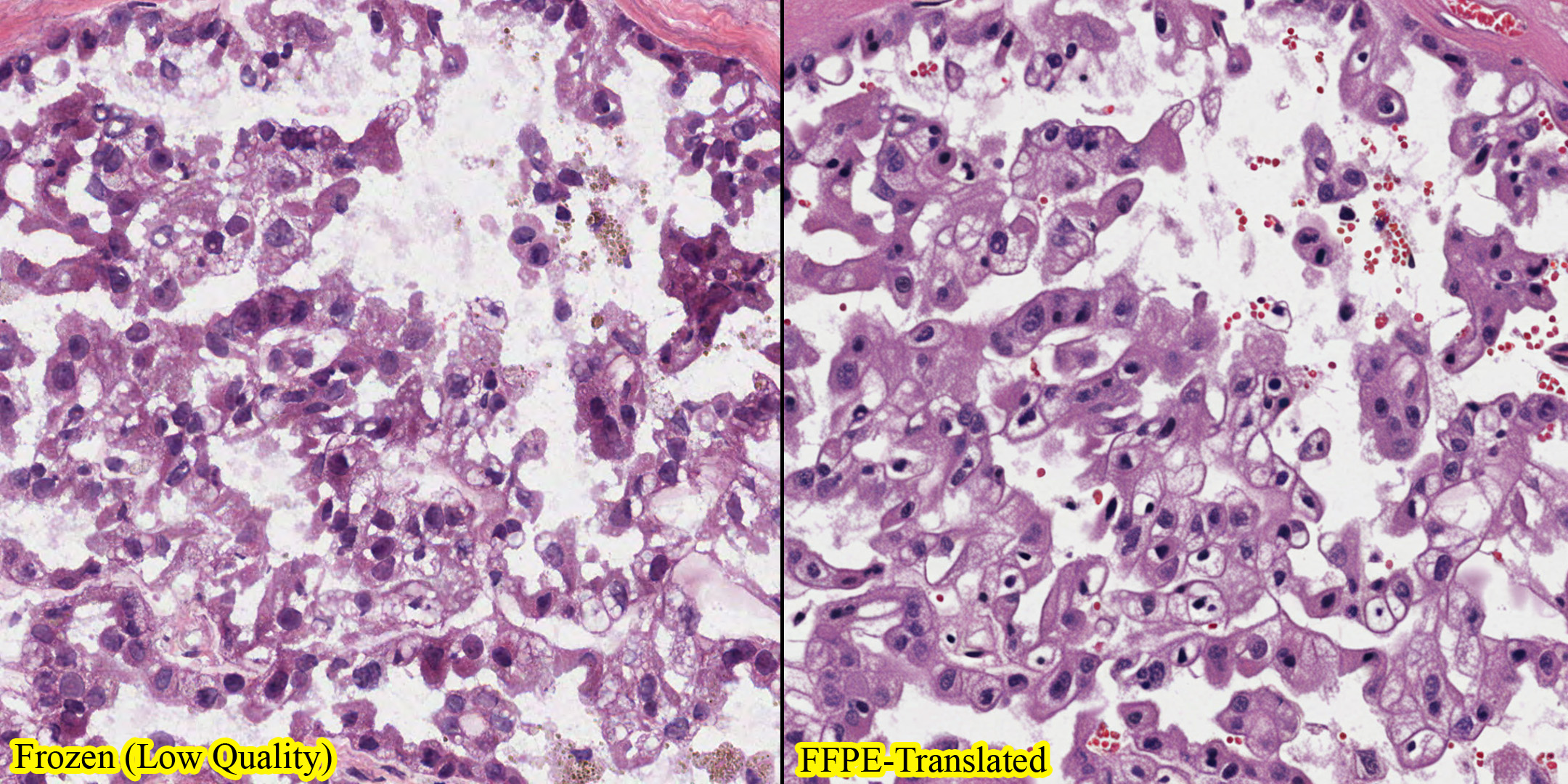
Proposed a new supervised color style transfer technique based on low-level transformations.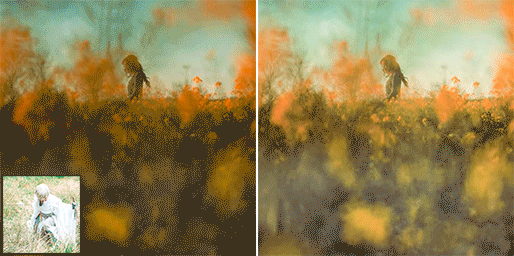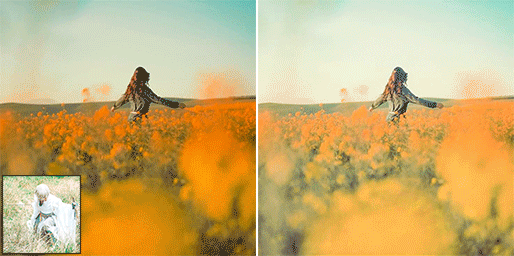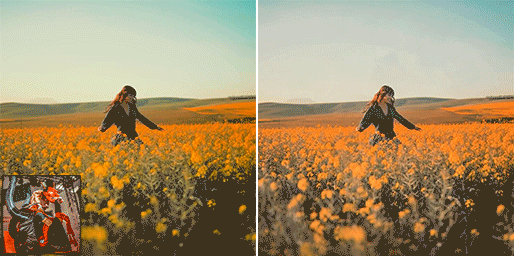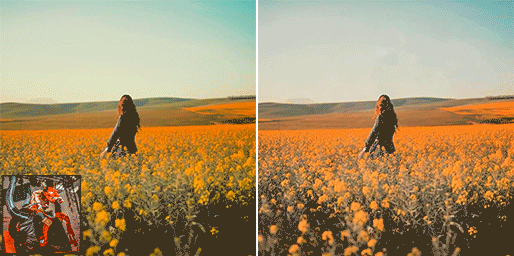
Proposed a self-distillation strategy for Latent Diffusion Models to improve the accuracy in mask-to-histopathology image translation.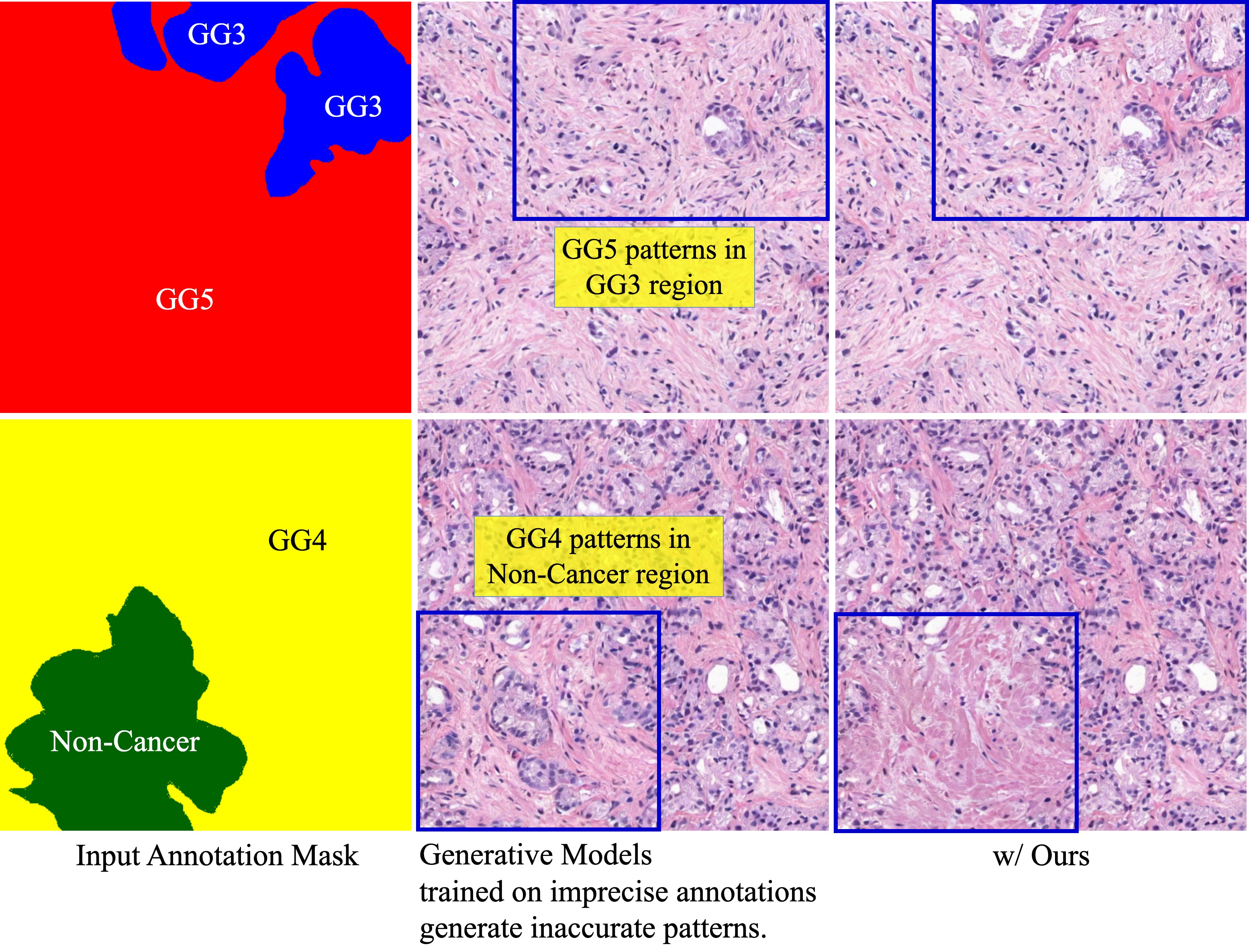
ACM SIGGRAPH European Conference on Visual Media Production (CVMP), 2019
Man M. Ho (Minh-Man Ho), Jinjia Zhou, Yibo Fan
Respecting low-level components of content with skip connections and semantic information in image style transfer.
Paper | Webpage | GitHub | Demo | Comparison Video
International Conference on Multimedia Modeling (MMM), 2020
Man M. Ho (Minh-Man Ho), Gang He, Zheng Wang, Jinjia Zhou
Best Paper Runner-up Award at MMM2020.
Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2020
Man M. Ho, Jinjia Zhou, Gang He, Muchen Li, Lei Li
Top-5 performance among teams which have submitted a factsheet on P-frame Track, CLIC2020.
Paper | Webpage | Presentation
VizWiz Workshop, 2020
Huyen T. T. Bui, Man M. Ho, Xiao Peng, Jinjia Zhou
Japanese coins and banknotes recognition for visually impaired people.
Winter Conference on Applications of Computer Vision (WACV), 2021
Man M. Ho, Jinjia Zhou
Proposed a novel color style transfer method. Lightroom Preset now can be any well-retouched photos.
IEEE Transactions on Image Processing (TIP), 2021
Man M. Ho, Jinjia Zhou, Gang He
Investigated the effect of compression degradation for training. Proposed a new learned down-sampling-based video coding framework.
Paper | Webpage | GitHub | Comparison Video
ACM SIGGRAPH European Conference on Visual Media Production (CVMP), 2021
Man M. Ho, Lu Zhang, Alexander Raake, Jinjia Zhou
Semantic-driven colorization for image and video.
Winter Conference on Applications of Computer Vision (WACV), 2022
Man M. Ho, Jinjia Zhou
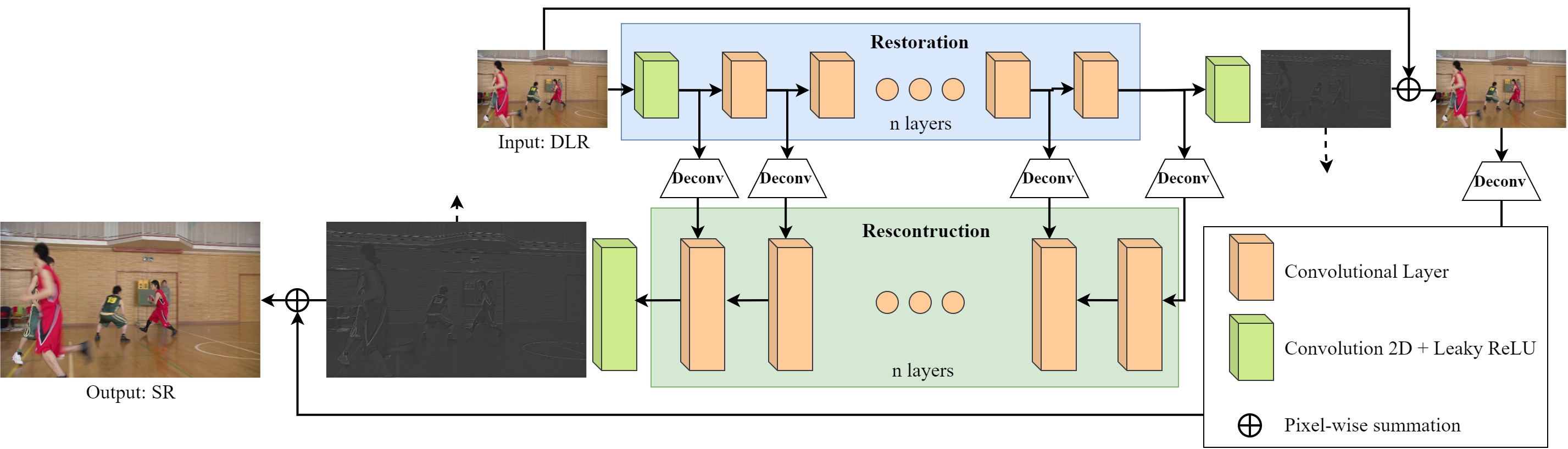
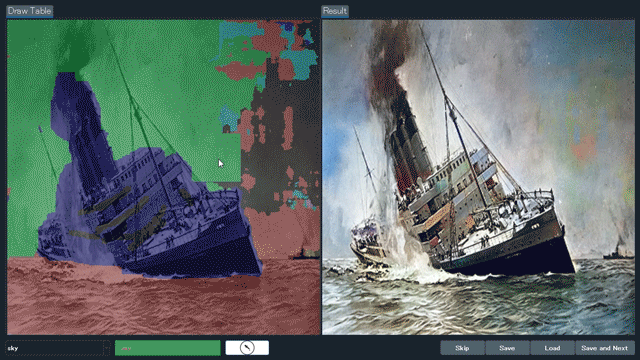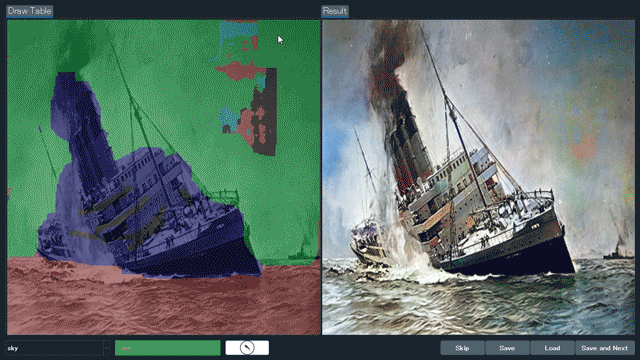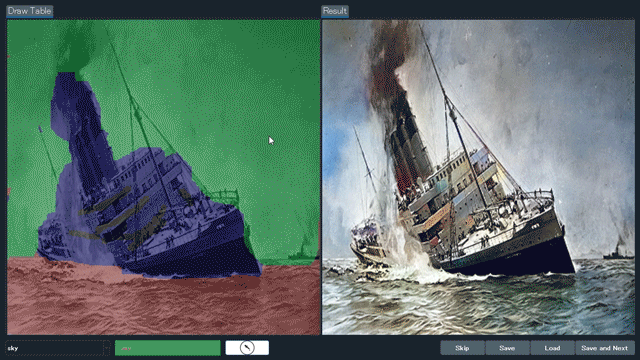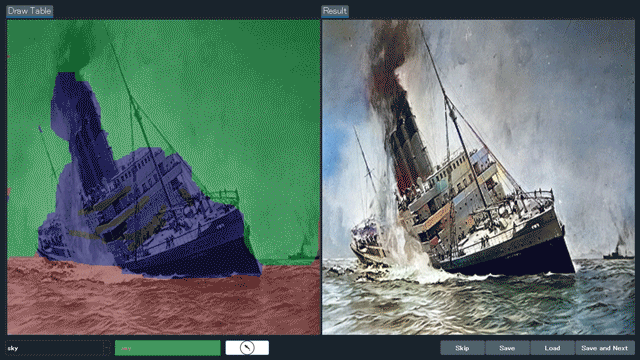
A promising baseline for learned smartphone-scanned photo restoration.
IEEE International Conference on Multimedia and Expo (ICME), 2022
Zhiqiang Zhang, Chen Fu, Man M. Ho, Jinjia Zhou, Ning Jiang, Wenxin Yu
Text-guided image manipulation based on sentence-aware and word-aware network.
IEEE International Conference on Visual Communications and Image Processing (VCIP), 2022
Man M. Ho, Heming Sun, Zhiqiang Zhang, Jinjia Zhou
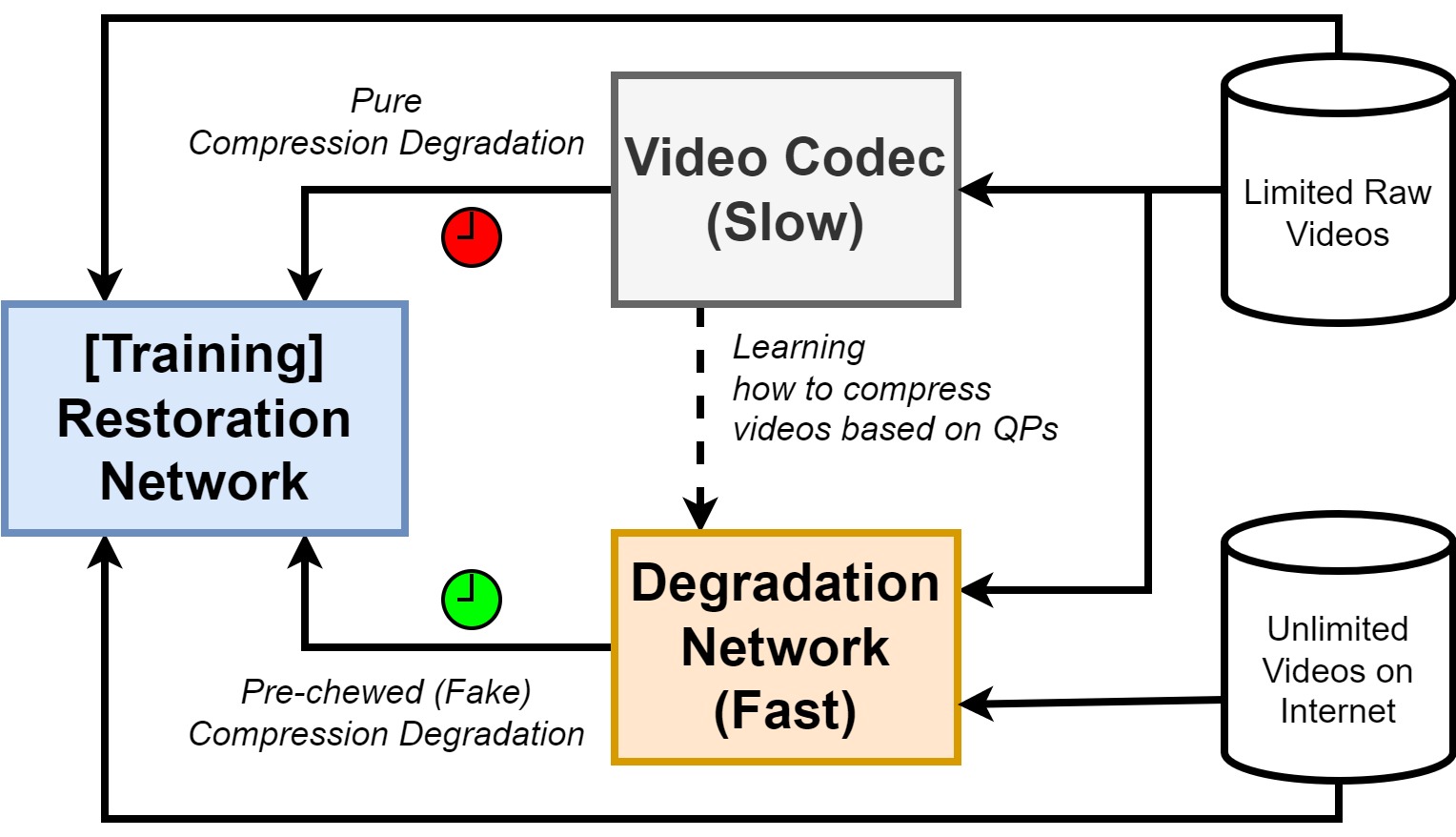
Pre-chewing compression degradation for learned video compression.
Winter Conference on Applications of Computer Vision (WACV), 2023
Ryugo Morita, Zhiqiang Zhang, Man M. Ho, Jinjia Zhou
Interactive image manipulation with complex text instructions.
Modern Pathology, 2024
Alessandro Ferrero, Elham Ghelichkhan, Hamid Manoochehri, Man M. Ho, Daniel J. Albertson, Benjamin J. Brintz, Tolga Tasdizen, Ross T. Whitaker, and Beatrice S. Knudsen
A pathologist-guided and explainable workflow using histogram embedding for gland classification.
IEEE International Symposium on Biomedical Imaging (ISBI), 2024
Man M. Ho, Elham Ghelichkhan, Yosep Chong, Yufei Zhou, Beatrice S. Knudsen, and Tolga Tasdizen
Developed Latent Diffusion Models (LDMs) to generate high-fidelity histopathology images for training prostate cancer grading models.
Winter Conference on Applications of Computer Vision (WACV), 2025
Man M. Ho, Shikha Dubey, Yosep Chong, Beatrice S. Knudsen, and Tolga Tasdizen
Developed LDMs with Parameter-Efficient Fine-Tuning (PEFT) and Histopathology Pre-Trained Embeddings for translating low-quality frozen section images to high-quality FFPE images.
Medical Image Analysis, 2025
Bodong Zhang, Hamid Manoochehri, Man M. Ho, Fahimeh Fooladgar, Yosep Chong, Beatrice S. Knudsen, Deepika Sirohi, and Tolga Tasdizen
Adaptive stain separation-based contrastive learning with pseudo-labeling for histopathological image classification.
Medical Imaging with Deep Learning (MIDL), 2025
Xiaoya Tang, Bodong Zhang, Man M. Ho, Beatrice S. Knudsen, Tolga Tasdizen
Leveraging Hierarchical Representations by Local and Global Attention Vision Transformer.
Published:
This is a description of your talk, which is a markdown file that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.


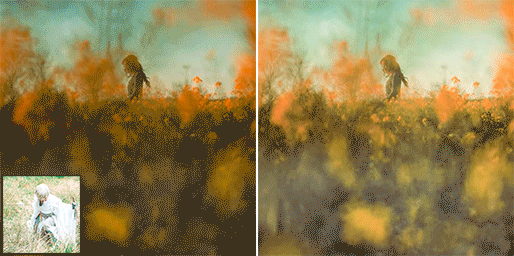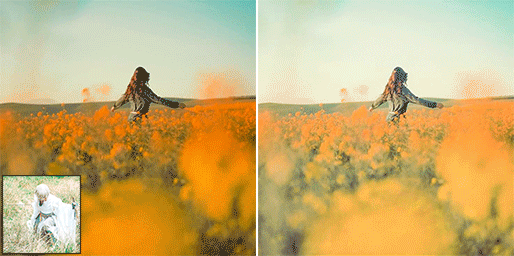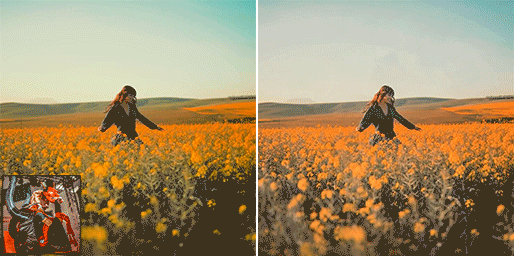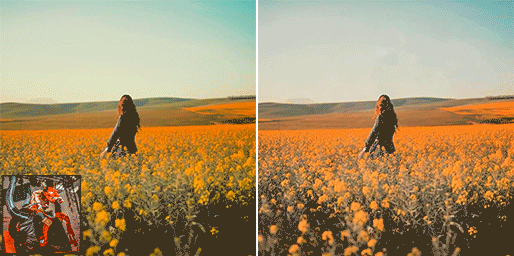





{kind=link}