On Pre-chewing Compression Degradation for Learned Video Compression
| Man M. Ho1 | Heming Sun2,3 | Zhiqiang Zhang1 | Jinjia Zhou1 |
| 1. Hosei Univerisity, Tokyo, Japan | 2. Waseda University, Tokyo, Japan | 3. JST PRESTO, Tokyo, Japan |
| [Paper] | [Source Code] |
In IEEE International Conference on Visual Communications and Image Processing (VCIP), 2022
Abstract
Artificial Intelligence (AI) needs huge amounts of data, and so does Learned Restoration for Video Compression. There are two main problems regarding training data. 1) Preparing training compression degradation using a video codec (e.g., Versatile Video Coding - VVC) costs a considerable resource. Significantly, the more Quantization Parameters (QPs) we compress with, the more coding time and storage are required. 2) The common way of training a newly initialized Restoration Network on pure compression degradation at the beginning is not effective. To solve these problems, we propose a Degradation Network to pre-chew (generalize and learn to synthesize) the real compression degradation, then present a hybrid training scheme that allows a Restoration Network to be trained on unlimited videos without compression. Concretely, we propose a QP-wise Degradation Network to learn how to compress video frames like VVC in real-time and can transform the degradation output between QPs linearly. The real compression degradation is thus pre-chewed as our Degradation Network can synthesize the more generalized degradation for a newly initialized Restoration Network to learn easier. To diversify training video content without compression and avoid overfitting, we design a Training Framework for Semi-Compression Degradation (TF-SCD) to train our model on many fake compressed videos together with real compressed videos. As a result, the Restoration Network can quickly jump to the near-best optimum at the beginning of training, proving our promising scheme of using pre-chewed data for the very first steps of training. In other words, a newly initialized Learned Video Compression can be warmed up efficiently but effectively with our pre-trained Degradation Network. Besides, our proposed TF-SCD can further enhance the restoration performance in a specific range of QPs and provide a better generalization about QPs compared with the common way of training a restoration model.
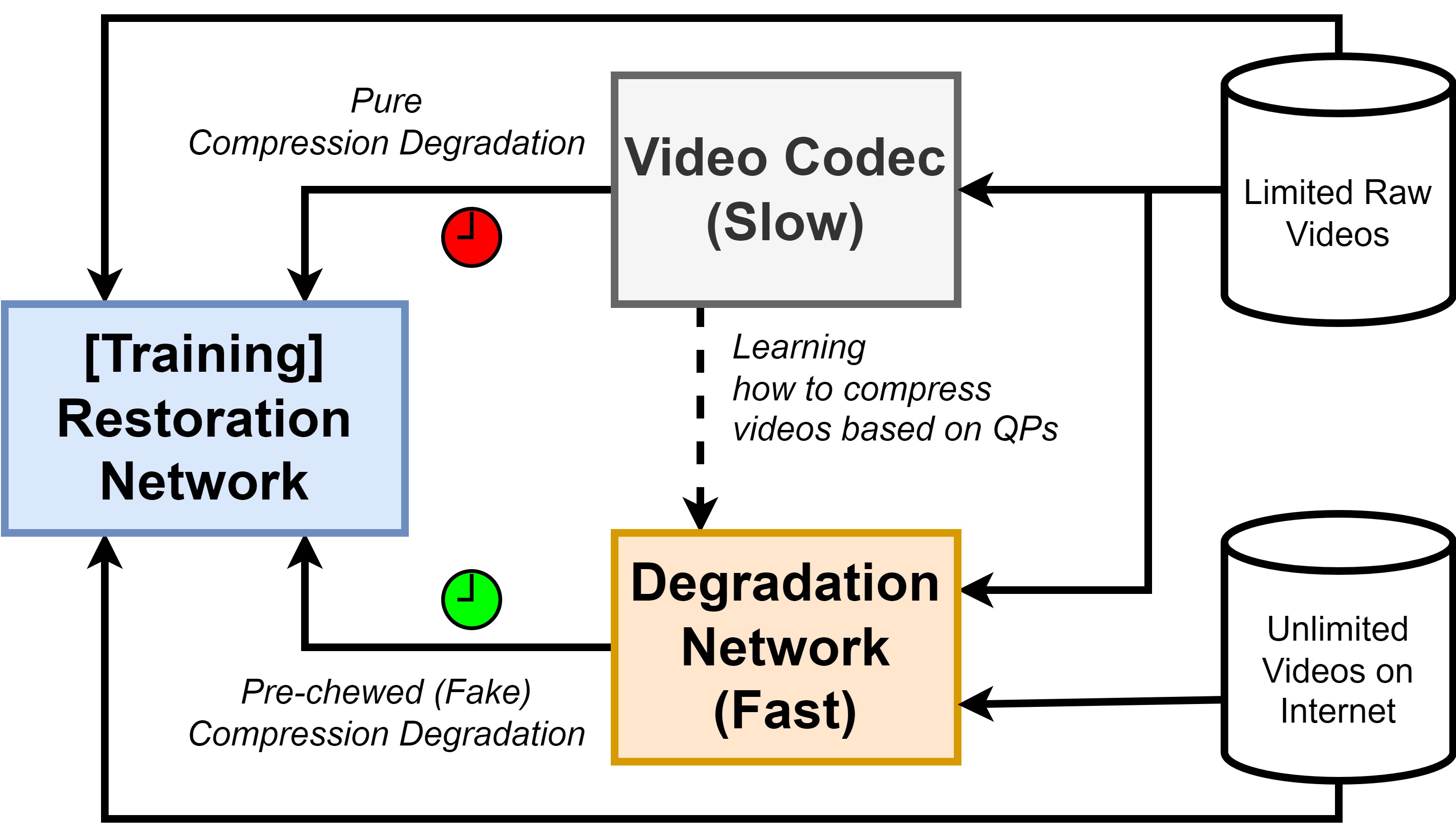
Overall Concept
Figure: Our Training Framework for Semi-Compression Degradation.
We train a QP-wise Degradation Network to learn and synthesize compression degradation
for an unlimited number of videos on the Internet. As an advantage,
the Restoration Network can be trained on more video frames without compression,
diversifying training video content and QPs.
Network Architecture
Ablation study on metrics to learn compression degradation
Table: Ablation study on loss functions such as L1, L2, and LPIPS
for generating compression degradation. The combination of L1 and LPIPS provides the best
performance in PSNR, LPIPS, and MS-SSIM on average as bold.
| Quantization Parameters | L2 | L1 | L1+LPIPS↓ | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | LPIPS↓ | MS-SSIM↑ | PSNR↑ | LPIPS↓ | MS-SSIM↑ | PSNR↑ | LPIPS↓ | MS-SSIM↑ | |
| 32 | 36.31 | 0.0910 | 0.9668 | 37.92 | 0.0476 | 0.9777 | 38.42 | 0.0368 | 0.9799 |
| 35 | 36.03 | 0.0958 | 0.9647 | 37.49 | 0.0570 | 0.9757 | 37.99 | 0.0428 | 0.9781 |
| 37 | 35.95 | 0.0976 | 0.9657 | 37.25 | 0.0630 | 0.9763 | 37.71 | 0.0476 | 0.9782 |
| 40 | 35.57 | 0.1001 | 0.9628 | 36.59 | 0.0721 | 0.9728 | 36.93 | 0.0566 | 0.9747 |
| 42 | 35.27 | 0.1026 | 0.9606 | 36.09 | 0.0790 | 0.9701 | 36.33 | 0.0640 | 0.9718 |
| 45 | 34.74 | 0.1084 | 0.9560 | 35.22 | 0.0936 | 0.9645 | 35.33 | 0.0785 | 0.9658 |
| 47 | 34.27 | 0.1157 | 0.9519 | 34.53 | 0.1086 | 0.9592 | 34.57 | 0.0941 | 0.9603 |
| Avg. | 35.45 | 0.1016 | 0.9612 | 36.44 | 0.0744 | 0.9709 | 36.76 | 0.0601 | 0.9727 |
Comparison
Table: Quantitative Comparison on Restoration Performance between DnCNN trained on S-Set
with Real QPs={32,37,42,47} and S-Set with Real QPs={32,37,42,47} combined with U-Set
with Fake QPs={32,35,37,40,42,45,47} on videos from the Internet using PSNR, LPIPS, MS-SSIM.
Our method outperforms the common way in a QP range of [22 .. 51] as highlighted rows.
| Quantization Parameters | The Common Way | Our Way | ||||
|---|---|---|---|---|---|---|
| PSNR↑ | LPIPS↓ | MS-SSIM↑ | PSNR↑ | LPIPS↓ | MS-SSIM↑ | |
| 17 | 42.69 | 0.0189 | 0.9880 | 42.53 | 0.0177 | 0.9875 |
| 22 | 40.87 | 0.0312 | 0.9837 | 40.92 | 0.0243 | 0.9839 |
| 27 | 39.60 | 0.0390 | 0.9788 | 39.68 | 0.0312 | 0.9793 |
| 32 | 38.23 | 0.0494 | 0.9718 | 38.32 | 0.0421 | 0.9725 |
| 35 | 37.31 | 0.0592 | 0.9662 | 37.40 | 0.0522 | 0.9670 |
| 37 | 36.54 | 0.0677 | 0.9591 | 36.59 | 0.0621 | 0.9597 |
| 40 | 35.52 | 0.0833 | 0.9508 | 35.55 | 0.0785 | 0.9514 |
| 42 | 34.80 | 0.0960 | 0.9444 | 34.81 | 0.0918 | 0.9451 |
| 45 | 33.72 | 0.1195 | 0.9340 | 33.73 | 0.1170 | 0.9347 |
| 47 | 32.92 | 0.1398 | 0.9245 | 32.92 | 0.1383 | 0.9250 |
| 51 | 31.22 | 0.1984 | 0.8997 | 31.22 | 0.1978 | 0.9003 |
Consider citing our work
@inproceedings{ho2022pre,
title={On Pre-chewing Compression Degradation for Learned Video Compression},
author={Ho, Man Minh and Sun, Heming and Zhang, Zhiqiang and Zhou, Jinjia},
booktitle={2022 IEEE International Conference on Visual Communications and Image Processing (VCIP)},
pages={1--5},
year={2022},
organization={IEEE}
}
License
This work (as well as its materials) is for non-commercial uses and research purposes only.